| Command | Effect |
|---|---|
| git init | puts current directory and all its subdirs under version control. |
| git status | shows status |
| git add filename.py | adds file to tracked files |
| git commit -m “meaningful msg” | creates a new version/commit out of all staged files |
| git log | shows log of all commit messages on a branch |
| git checkout some-commit-id | goes to commit, but in detached HEAD state |
| git checkout main-branch-name | leaves temporary state, goes back to last commit |
5 Git Version Control
As stated before, may be the single most important thing to take away from Research Software Engineering if you have not used it before. In this chapter about the way developers work and collaborate, I will stick to with git. The stack discussion of the previous chapter features a few more systems, but given git’s dominant position, we will stick solely to git in this introduction to version control.
5.1 What Is Git Version Control?
Git is a decentralized version control system. It manages different versions of your source code (and other text files) in a simple but efficient manner that has become the industry standard: The git program itself is a small console program that creates and manages a hidden folder inside the folder you put under (you know those folders with a leading dot in their folder name, like .myfolder). This folder keeps track of all differences between the current version and other versions before the current one.
The key to appreciating the value of git is to appreciate the value of semantic versions. Git is not Dropbox nor Google Drive. It does not sync automagically (even if some Git GUI Tools suggest so). GUI tools GitHub Desktop1, Atlassian’s Source Tree2 and Tortoise3 are some of the most popular choices if you are not a console person. Though GUI tools may be convenient, we will use the git console throughout this book to improve our understanding. As opposed to the sync approaches mentioned above, a system allows summarizing a contribution across files and folders based on what this contribution is about. Assume you got a cool pointer from an econometrics professor at a conference, and you incorporated her advice in your work. That advice is likely to affect different parts of your work: your text and your code. As opposed to syncing each of these files based on the time you saved them, creates a version when you decide to bundle things together and to commit the change. That version could be identified easily by its commit message “incorporated advice from Anna (discussion at XYZ Conference 2020)”.
5.2 Why Use Version Control in Research?
A based workflow is a path to your goals that rather consists of semantically relevant steps instead of semantically meaningless chunks based on the time you saved them.
In other, more blatant, applied words: naming files like final_version_your_name.R or final_final_correction_collaboratorX_20200114.R is like naming your WiFi dont_park_the_car_in_the_frontyard or be_quiet_at_night to communicate with your neighbors. Information is supposed to be sent in a message, not a file name. With , it is immediately clear what the most current version is, no matter the file name. There is no room for interpretation. There is no need to start guessing about the delta between the current version and another version.
Also, you can easily try out different scenarios on different branches and merge them back together if you need to. is a well-established industry standard in software development. And it is relatively easy to adopt. With datasets growing in complexity, it is only natural to improve management of the code that processes these data.
Academia has probably been the only place that would allow you to dive into hacking at somewhat complex problems for several years without ever taking notice of . As a social scientist who rather collaborates in small groups and writes moderate amount of code, have you ever thought about how to collaborate with more 100 than persons in a big software project? Or to manage 10,000 lines of code and beyond? is an important reason these things work. And it’s been around for decades. But enough about the rant.
5.3 How Does Git Work?
This introduction tries to narrow things down to the commands that you’ll need if you want to use git in similar fashion to what you learn from this book. If you are looking for more comprehensive, general guides, three major git platforms, namely, Atlassian’s Bitbucket, GitHub and GitLab offer comprehensive introductions as well as advanced articles or videos to learn git online.
The first important implication of decentralized is that all versions are stored on the local machines of every collaborator, not just on a remote server (this is also a nice, natural backup of your work). So let’s consider a single local machine first.
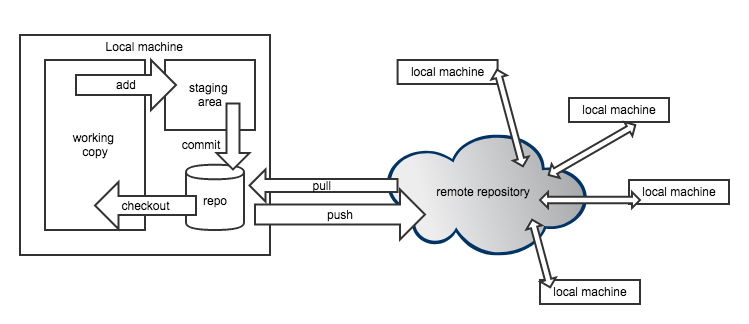
Locally, a git repository consists of a checkout which is also called current working copy. This is the status of the file that your file explorer or your editor will see when you use them to open a file. To check out a different version, one needs to call a commit by its unique commit hash and check out that particular version.
If you want to add new files to or bundle changes to some existing files into a new commit, add these files to the staging area, so they get committed next time a commit process is triggered. Finally, committing all these staged changes under another commit ID, a new version is created.
5.4 Moving Around
So let’s actually do it. Here’s a three-stage walk-through of git commands that should have you covered in most use cases a researcher will face. Note that git has some pretty good error messages that guess what could have gone wrong. Make sure to read them carefully. Even if you can’t make sense of them, your online search will be a lot more efficient when you include these messages.
Stage 1: Working Locally
Table 5.1 summarizes essential git commands to move around your local repository.
Stage 2: Working with a Remote Repository
Though git can be tremendously useful even without collaborators, the real fun starts when working together. The first step en route to getting others involved is to add a remote repository. Table 5.2 shows essential commands for working with a remote repository.
| Command | Effect |
|---|---|
| git clone | creates a new repo based on a remote one |
| git pull | gets all changes from a linked remote repo |
| git push | deploys all commit changes to the remote repo |
| git fetch | fetches branches that were created on remote |
| git remote -v | shows remote repo URL |
| git remote set-url origin https://some-url.com | sets URL to remote repo |
Stage 3: Branches
Branches are derivatives from the main branch that allow to work on different features at the same time without stepping on someone else’s feet. Through branches, repositories can actively maintain different states. Table 5.3 shows commands to navigate these states.
| Command | Effect |
|---|---|
| git checkout -b branchname | creates new branch named branchname |
| git branch | shows locally available branches |
| git checkout branchname | switches to branch named branchname |
| git switch branchname | switches to branch named branchname |
| git merge branchname | merges branch named branchname into current branch |
Fixing Merge Conflicts
In most cases, git is quite clever and can figure out which is the desired state of a file when putting two versions of it together. When git’s recursive strategy is possible, git will merge versions automatically. When the same lines were affected in different versions, git cannot tell which line should be kept. Sometimes, you would even want to keep both changes.
But even in such scenario, fixing the conflict is easy. Git will tell you that your last command caused a merge conflict and which files are conflicted. Open these files and take a look at all parts of the files in question. Figure 5.1 shows a situation in which trying merge a file that had changes across different branches caused a conflict.
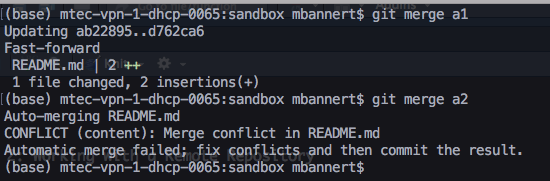
Luckily, git marks the exact spot where the conflict happens. Good text editors/IDEs ship with cool colors to highlight all our options. Some of the fancier editors even have git conflict resolve plugins that let you walk through all conflict points.
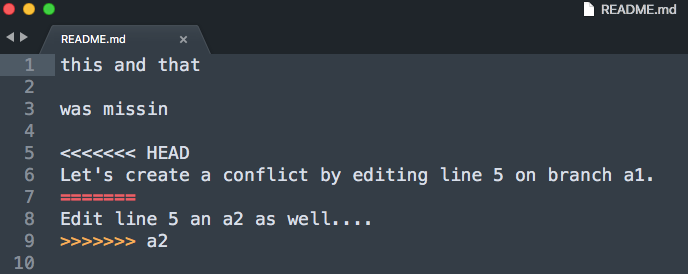
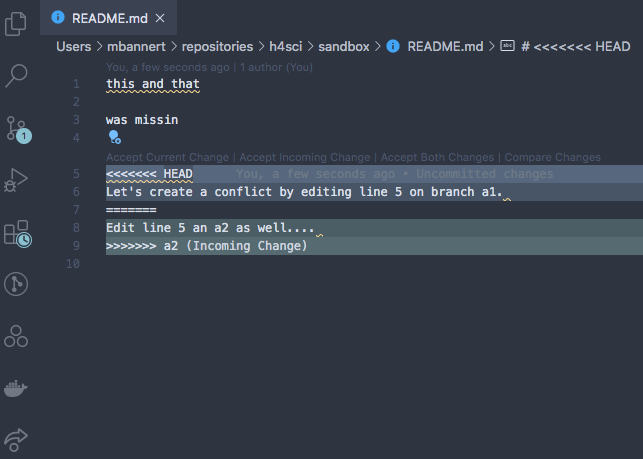
At the end of the day, all do the same, i.e., remove the unwanted part, including all the marker gibberish. After you have done so, save, commit and push (if you are working with a remote repo). Don’t forget to make sure you kinked out all conflicts.
5.5 Collaboration Workflow
The broad acceptance of git as a framework for collaboration has certainly played an important role in git’s establishment as an industry standard.
5.5.1 Feature Branches
This section discusses real-world collaboration workflows of modern open source software developers. Hence, the prerequisites to benefitting the most from this section are bit different. Make sure you are past the mere ability to describe and explain git basics, make sure you can create and handle your own repositories.
If you had only a handful of close collaborators so far, you may be fine with staying on the main branch and trying not to step on each other’s feet. This is reasonable because, git aside, it is rarely efficient to work asynchronously on exact the same lines of code anyway. Nevertheless, there is a reason why feature-branch-based workflows became very popular among developers: Imagine yourself collaborating in asynchronous fashion, maybe with someone in another time zone. Or with a colleague, who works on your project, but in a totally different month during the year. Or, most obviously, with someone you have never met. Forks and feature-branch-based workflows are the way a lot of modern open source projects tackle the above situations.
Forks are just a way to contribute via feature branches, even in case you do not have write access to a repository. But let’s just have a look at the basic feature branch case, in which you are part of the team first with full access to the repository. Assume there is already some work done, some version of the project is already up on a some remote GitHub account. You join as a collaborator and are allowed to push changes now. It’s certainly not a good idea to simply add things without review to a project’s production. Like if you got access to modify the institute’s website, and you made your first changes and all your changes go straight to production. Like this:
Bet everybody on the team took notice of the new team member by then. In a feature branch workflow, you would start from the latest production version. Remember, git is decentralized, and you have all versions of your team’s project on your local machine. Create a new branch named indicative of the feature you are looking to work on.
git checkout -b colorwaysYou are automatically being switched to the freshly created branch. Do your thing now. It could be just a single commit, or several commits by different persons. Once you are done, i.e., committed all changes, add your branch to the remote repository by pushing.
git push -u origin colorwaysThis will add your branch called colorways to the remote repository. If you are on any major git platform with your project, it will come with a decent web GUI. Such a GUI is the most straightforward way to do the next step: get your Pull Request (PR) out.
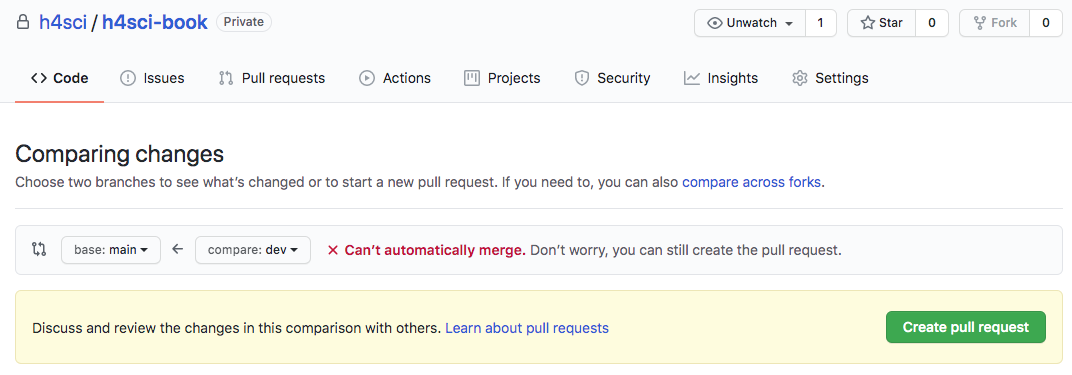
As you can see, git will check whether it is possible to merge automatically without interaction. Even if that is not possible, you can still issue the pull request. When you create the request, you can also assign reviewers, but you could also do so at a later stage.
Even after a PR was issued, you can continue to add commits to the branch about to be merged. As long as you do not merge the branch through the PR, commits are added to the branch. In other words, your existing PR gets updated. This is a very natural way to account for reviewer comments.
Note
Use commit messages like ‘added join to SQLquery, closes #3’. The keyword ‘closes’ or ‘fixes’, will automatically close issues referred to when merged into the main branch.
Once the merge is done, all your changes are in the main branch, and you and everyone else can pull the main branch that now contains your new feature. Yay!
5.5.2 Pull Requests from Forks
Now, let’s assume you are using an open source software created by someone else. At some point, you miss a feature that you feel is not too hard to implement. After googling and reading up a bit, you realize others would like to have these features, too, but the original authors did not find the time to implement it yet. Hence, you get to work. Luckily, the project is open source and up on GitHub, so you can simply get your version of it, i.e., fork the project to your own GitHub account (just click the fork button and follow the instructions) .
Now that you have your own version of the software with all the access rights to modify it, you can implement your feature and push it to your own remote git repository. Because you forked the repository, your remote git platform will still remember where you got it from and allows you to issue a pull request to the original author. The original authors can now review the pull request, see the changes, and decide whether they are fine with the feature and its implementation.
There may very well be some back and forth in the message board before the pull requests gets merged. But usually these discussions are very context-aware and sooner or later, you will get your first pull request approved and merged. In that case, congratulations – you have turned yourself into a team-oriented open source collaborator!
5.5.3 Rebase vs. Merge
Powerful systems often provide more than one way to achieve your goals. In the case of git, putting together two branches of work – a very vital task, is exactly such a case: We can either merge or rebase branches.
While merge keeps the history intact, rebase is a history-altering command. Though most people are happy with the more straightforward merge approach, a bit of context is certainly helpful.
Imagine the merge approach as a branch that goes away from the trunk at some point and then grows alongside the trunk in parallel. In case both histories become out of sync because someone else adds to the main branch while you keep adding to the feature branch, you can either merge or rebase to put the two together.
Sitting on a checkout of the feature branch, a merge of the main branch would simply create an additional merge commit sequentially after the last commit of the feature branch. This merge commit contains the changes of both branches, no matter if they were automatically merged using the standard recursive strategy or through resolving a merge conflict.
As opposed to that, rebase would move all changes to main to before the feature branch started, then sequentially add all commits of the feature branch. That way your history remains linear, looks cleaner and does not contain artificial merge commits.
So, when should we merge, and when should we rebase? There is no clear rule to that other than to not use rebase on exposed branches such as main because you would have a different main branch than other developers. Rebase can ruin your collaborative workflow, yet it helps to clean up. In my opinion, merging feature branches is just fine for most people and teams. So unless you have too many people working on too many different features at once and are in danger of not being able to move through your history, simply go with the merge approach. The following Atlassian tutorial4 offers more insights and illustrations to deepen your understanding of the matter.